

Ao criar o walkthrough para o WKS neste artigo, precisei obter uma base de informações sobre filmes, o que você encontra aos montes na internet em diversos sites. Claro que ninguém teria tempo nem o trabalho de entrar filme por filme e copiar manualmente todas as informações que você encontra separando arquivo por arquivo. Ai que entra o crawler, quando você precisa obter informações na internet de um ou mais sites, para que possa tratar os dados com uma finalidade especifica, no meu caso, gerar arquivos de informações de filmes.
O crawler nada mais é que um programa que navega nos sites e lê sua estrutura de dados. Para desenvolver uma aplicação que faça isso, você precisa estudar como o código do site está estruturado e então começar a brincadeira.
a fonte de origem dos filmes que escolhi foi o http://www.adorocinema.com (vai ai uma propaganda gratuita), que é um site que acompanho criticas de cinema e possui as informações que preciso.
Entendendo a estrutura do site
O primeiro passo é entender como esta organizado o html do site
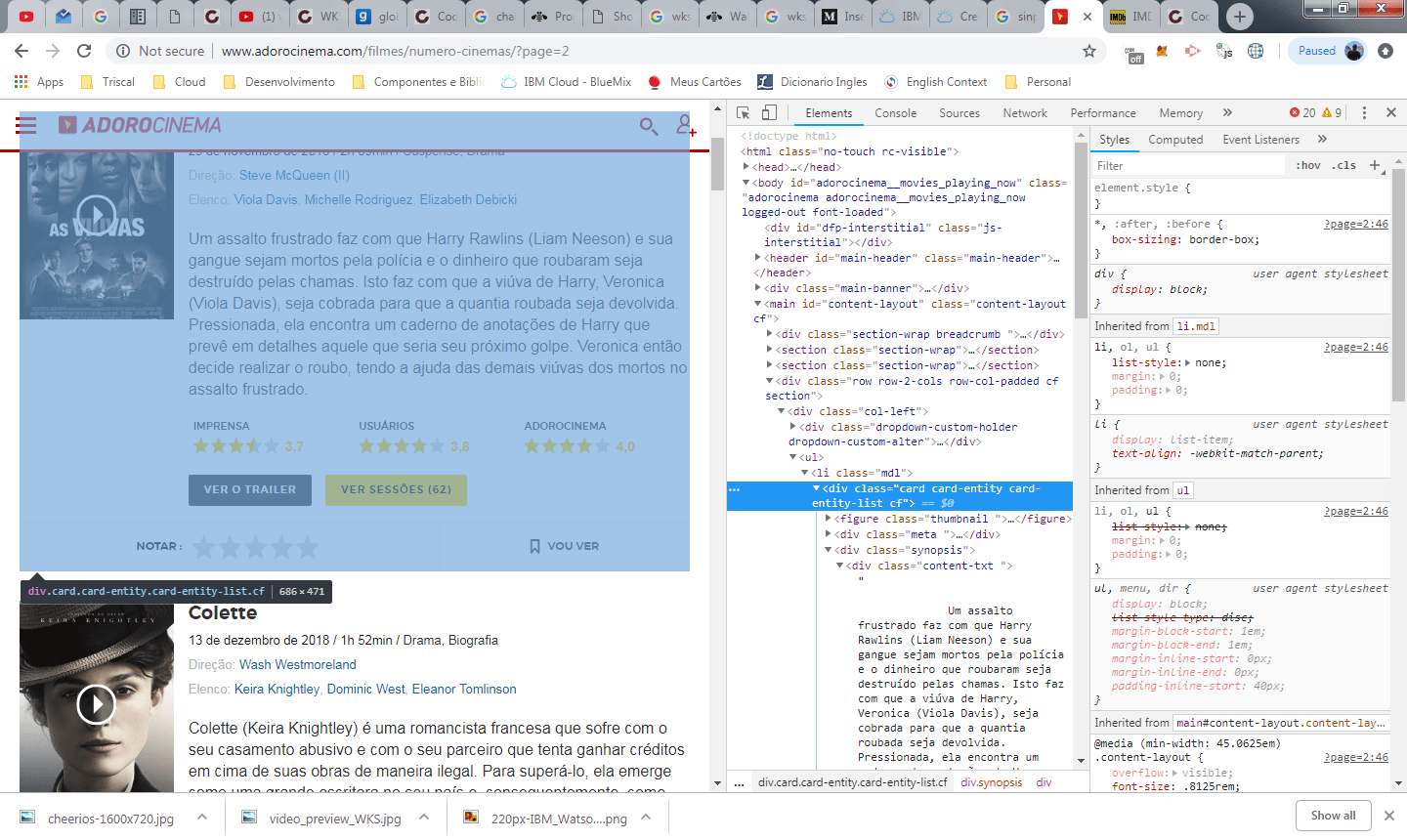
no print acima, estou acessando a pagina 2 a partir da URL http://www.adorocinema.com/filmes/numero-cinemas/?page=2. Esta é a segunda página da lista de filmes que estão em cartaz no cinema no momento (aproveitando, Aquaman está bombando com toda razão, finalmente a DC acertou a mão).
Outra informação importante do site que vamos utilizar é a <div> que destaquei no console do google chrome. a classe css card-entity-list, é adicionada em todas as divs que representam cada bloco contendo informações de um filme. Ainda sem codificar, nossa logica precisa de certa maneira fazer o seguinte:
- Navegar pelas paginas do site adicionando no final de cada URL o parâmetro “page=X”, onde X é um contador de pagina que começa em 1 e vai até não existirem mais filmes para processar, que neste caso é a pagina 6.
- Em cada pagina, realizar um loop entre todas as ocorrências do DOM que possuem a classe card-entity-list, para dentro de cada uma delas obter o conteúdo desejado.
Code
A partir deste ponto já podemos escrever o código do nosso crawler, que está publicado por completo logo abaixo:
[cc lang=”javascript”]
var request = require(‘request’)
var cheerio = require (‘cheerio’)
var fs = require(‘fs’)
for (var i = 1; i <= 6; i++) {
var url = ‘http://www.adorocinema.com/filmes/numero-cinemas/?page=’ + i;
request(url, function (err, res, body) {
if (err)
console.log (‘Erro’, err)
var $ = cheerio.load(body);
console.log(‘current dir: ‘ + __dirname)
var count = 1;
console.log(‘———————————————-‘);
console.log(‘iniciando busca por filmes no site adorocinema’);
console.log(‘———————————————-‘);
$(‘.col-left’).find(‘.card-entity-list’).each(function (){
if (count <= 100){
var nomeFilme = $(this).find(‘.meta-title’).text().trim();
var dataLancamento = $(this).find(‘.meta-body-info’).find(‘.date’).text().trim();
var sinopse = $(this).find(‘.content-txt ‘).text().trim();
var genero = null;
console.log(‘meta-body-info’, $(this).find(‘.meta-body-info’).find(‘span’).eq(3).text());
var countMetaInfo = 0;
$(this).find(‘.meta-body-info’).find(‘span’).each(function (){
if ($(this).text() != ‘/’ && countMetaInfo > 2){
if (genero != null)
genero = genero + “, “;
else
genero = “”;
genero = genero + $(this).text()
}
countMetaInfo++;
});
console.log(‘contador: ‘ + count);
console.log(‘nomeFilme:’ + nomeFilme);
console.log(‘dataLancamento:’ + dataLancamento);
console.log(‘genero:’ + genero);
console.log(‘sinopse:’ + sinopse);
console.log(”);
console.log(”);
nomeFilme = nomeFilme.replace(“:”, “”);
var content = “Nome do Filme: ” + nomeFilme + “\r\n”;
content = content + “Data de Lançamento: ” + dataLancamento + “\r\n”;
content = content + “Genero: ” + genero + “\r\n”;
content = content + sinopse + “\r\n”;
//salva o documento do filme
fs.appendFile(__dirname + ‘/filmes/’ + nomeFilme + ‘.txt’, content, function(err) {
if(err) {
return console.log(err);
}
console.log(“The file was saved!”);
});
}
count++;
});
});
}
[/cc]
se voce pegar o codigo acima e rodar no nodeJS ele irá executar sem erro (Caso o site não tenha modificado a sua estrutura).
o que o codigo faz?
[cc lang=”javascript”]
var request = require(‘request’)
var cheerio = require (‘cheerio’)
var fs = require(‘fs’)
[/cc]
O código acima esta importando as bibliotecas request e fs, responsáveis por realizar requisições http e de salvar e manipular arquivos no filesystem.
Importamos também a biblioteca do cheerio para construção do crawler, a instalação pode ser feita com um comando simples npm install cheerio. Para mais informações acesse o site oficial https://github.com/cheeriojs/cheerio
Apos a importação das bibliotecas, criamos um loop entre as seis paginas de navegação dos filmes em cartaz e para cada pagina fazemos uma requisição. Dentro de cada requisição usamos o comando abaixo para carregar o body da pagina no cheerio:
[cc lang=”javascript”]var $ = cheerio.load(body);[/cc]
com o body da pagina carregado, precisamos percorrer a estrutura de cada filme. Conforme foi abordado anteriormente, esta estrutura é uma div com a classe card-entity-list. Então fazemos um loop entre toda a estrutura com essa característica
[cc lang=”javascript”]
$(‘.col-left’).find(‘.card-entity-list’).each(function (){
[/cc]
dentro do each, nos temos o conteudo da div de cada filme com todas as suas informações (genero, data de lançamento, nome, atores e sinopse). Então dentro de cada each obtemos as informações que precisamos:
[cc lang=”javascript”]
var nomeFilme = $(this).find(‘.meta-title’).text().trim();
var dataLancamento = $(this).find(‘.meta-body-info’).find(‘.date’).text().trim();
var sinopse = $(this).find(‘.content-txt ‘).text().trim();
[/cc]
Olhando a estrutura da div de filmes, a estrutura parece bem simples de obter. O nome do filme está inserido dentro de uma classe chamada .meta-title. Quando usamos $(this).find(‘.meta-title’), estamos dizendo que dentro da div de filme (this), precisamos encontrar a classe meta-title, que possui em seu conteúdo o nome do filme .text().trim().
Os demais itens são obtidos de maneira semelhante e se você esta familiarizado com jQuery, vai perceber que a estrutura de busca é muito parecida.
no final do codigo salvamos para cada filme um arquivo no formato txt, mas neste caso não estamos mais falando do cheerio e sim da biblioteca de filesystem do nodejs.
[cc lang=”javascript”]
var content = “Nome do Filme: ” + nomeFilme + “\r\n”;
content = content + “Data de Lançamento: ” + dataLancamento + “\r\n”;
content = content + “Genero: ” + genero + “\r\n”;
content = content + sinopse + “\r\n”;
//salva o documento do filme
fs.appendFile(__dirname + ‘/filmes/’ + nomeFilme + ‘.txt’, content, function(err) {
if(err) {
return console.log(err);
}
console.log(“The file was saved!”);
});
[/cc]
o crawler pode ser utilizado para diversas funções e utilizado frequentemente na internet e sua construção é bem simples. É através dele por exemplo, que o google indexa as paginas da internet.


{kind=link}