

WKS é a ferramenta da IBM pra gerar modelos de machine learning que podem ser utilizados por outros serviços do Watson, como o Watson Discovery e o NLU (Natural Language Understanding).
Nesta primeira parte vamos abordar alguns conceitos e configurar o modelo até a execução do ground truth editor. A segunda parte deste
WalkThrough será composta pela analise dos resultados do modelo que foi treinado.
Para quem nunca teve contato com o WKS, acho importante dar exemplos reais da sua utilização. Recentemente participei de dois projetos que utilizaram a plataforma com os seguintes objetivos:
- Processamento em lote de milhares de documentos, onde cada documento era um chamado aberto no portal de reclamações da empresa. O WKS foi utilizado para gerar um modelo de machine learning pra que através do uso de NLU, pudesse identificar e categorizar cada um dos chamados.
- Treinamento de um chatbot para responder long-tail questions utilizando o modelo gerado pelo WKS
Caso, você tenha cenários onde precisa utilizar NLU para estruturar seus dados e precise gerar um modelo, vale muito a pena uma experiencia com essa ferramenta, para testa-la é totalmente gratuito e você pode começar no link abaixo:
https://www.ibm.com/watson/services/knowledge-studio/
Etapa 1 – preparando o modelo (ASSETS)
Apos instanciar o serviço do WKS dentro da cloud da IBM, o primeiro passo é criar um workspace. Não tem muito o que descrever nesta etapa, um workspace é onde você vai armazenar o modelo que será treinado. Para o nosso caso, vamos criar um modelo chamado cinegrama que deverá estruturar os textos em uma biblioteca de filmes.
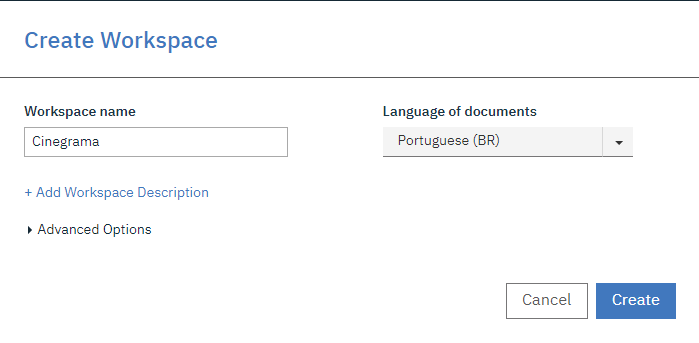
ENTIDADES
Criado o workspace, o primeiro passo é criar as entidades desejadas clicando em ENTITY TYPES. Neste momento precisamos ter definido o que nosso modelo precisas aprender a identificar num texto, o que você precisa extrair dele como entidade ?
Como estamos falando de filmes e vamos processar textos com informações sobre eles, podemos guardar informações como:
- Filme (nome)
- Data de Lançamento
- Atores
- Gênero
- Pais de Origem
Mention Class e Mention Types não podem ser modificados, eles servem pra qualificar uma parte do texto como Negação, Especifico ou Genérico no caso do mention class e em pronomes, nomes ou ordinais no caso do mention types.
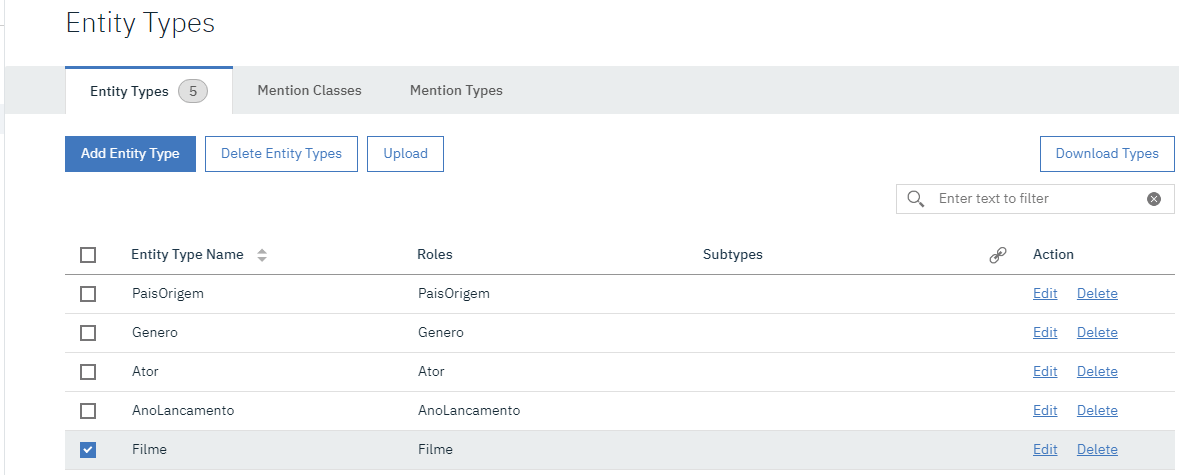
RELATION
O Segundo passo é relacionar as entidades entre sim da mesma forma que é feito um diagrama de entidades e relacionamento (DER). Exemplo: Empresa e Pessoa são entidades, Pessoa TrabalhaPara Empresa.
No nosso exemplo que relações nos temos entre nossas entidades?
- um Filme é produzido em um PaisOrigem
- um Filme possui um Genero
- um Ator atua em um Filme
- um Filme é lançado em um AnoLancamento
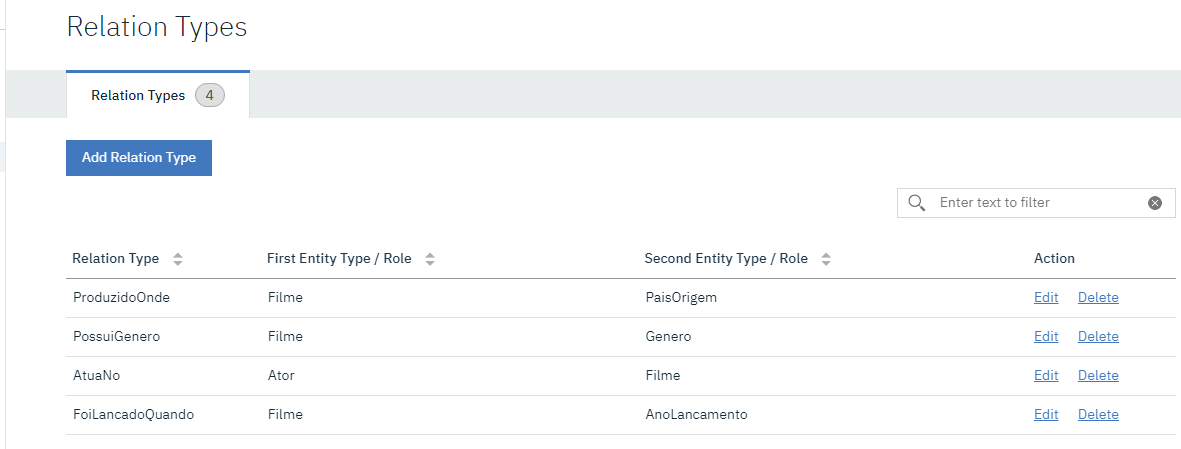
DICTIONARY
O Terceiro passo é criar um dicionario. Este passo não é obrigatório, mas ele ajuda no treinamento do modelo de machine learning. O dicionario é usado para relacionar palavras que são parecidas, ajudando dessa forma uma melhor compreensão do domínio que esta sendo criado.
Em machine learning, dicionários servem para agrupar palavras e frases que compartilham algo em comum. Uma entrada em um dicionario não significa que todas as outras entradas do dicionário tenham o mesmo significado (não são sinônimos).
Considere o exemplo: uma entrada de dictionary contem os 7 dias da semana (segunda, terça …). Ao anotar um documento (vamos ver este passo mais a frente) atribuiu a entidade DAY_OF_WEEK as menções “segunda-feira” e “sexta-feira”. Por conta das entradas do dicionario que equacionam os 7 dias da semana, o dicionario garante que os outros 5 dias da semana serão anotados em tempo de execução, mesmo que o annotator (usuário responsável por anotar os documentos) não tenha processado os documentos.
Dentre as principais características de um dicionario temos o seguinte:
- É um passo opcional do modelo de machine learning
- Corresponde a um grupo de palavras ou frases que são similares
- Estão associados a uma entidade
- Um dicionario faz parte do que chamamos de fase de pré-anotação, pois ele deve ser executado antes que o anotador comece a trabalhar nos documentos.
- Os dados do dicionario podem ser importados e exportados em CSV de forma que sejam aproveitados em outros workspaces.
Nota: Você não precisa criar um dicionario com os dias da semana pois já existem dicionários embutidos na ferramenta. Como por exemplo: países, lugares, números, animais, plantas, doenças, unidades de medida e saudações. Você não pode desabilitar ou editar esses dicionários já embutidos.
No exemplo deste tutorial, o cinegrama, vamos criar um dicionario de gêneros para identificar filmes de terror, comedia e drama. Veja abaixo como ficou a configuração do dicionario
DOCUMENT SET
O Quarto passo é enviar os documentos que serão utilizados pra treinar o modelo de machine learning. Eles podem ser inseridos em diversos formatos, mas o que vamos utilizar são simples documentos no formato TXT que foram gerados a partir do nosso tutorial de crawler.
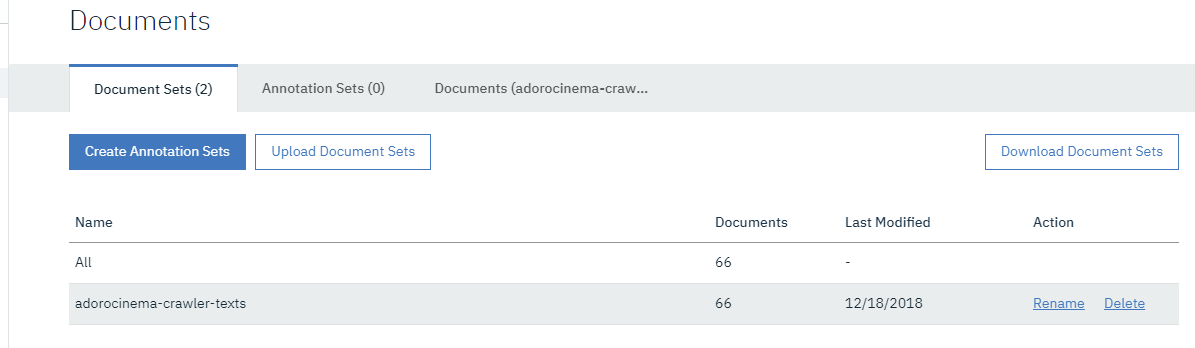
No exemplo abaixo foram importados 66 documentos para servir de instrução para o nosso modelo
Antes de seguir para a fase 2 onde será iniciado o treinamento do modelo, você deve criar SETS de annotations para que eles sejam alocados para ANNOTATORs (pessoas treinadas em WKS para treinar a I.A).
É importante que o annotator seja uma pessoa da equipe de usuários da ferramenta que vai utilizar o modelo e que essa pessoa tenha bastante conhecimento do negocio. As anotações para treinamento de modelo de machine learning não foram criadas para que a equipe de TI faça o treinamento, e sim o profissional com domínio do negocio.
Document Set: no nosso caso fizemos um upload com 66 arquivos TXT. Para este upload demos o nome de adorocinema-crawler-texts. então temos um document set com 66 documentos dentro dele.
Annotation Set: um document set pode ser associado a um ou mais annotation set, que é uma tarefa alocada a um annotator (pessoa responsável por treinar a I.A).
No nosso exemplo, vamos criar dois annotation sets para o documento set que foi importado
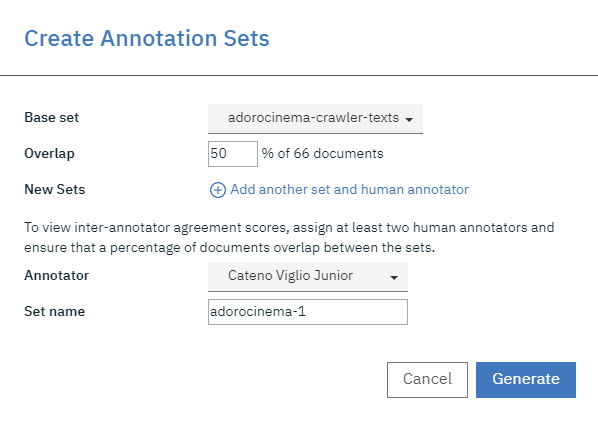
no exemplo acima, 50% do conteúdo do DOCUMENT SET “adorocinema-crawler-texts”, está sendo atribuído ao annotator “Cateno Viglio Junior”. Ele é responsável por 50% dos 66 documentos incluídos no DOCUMENT SET. O nome dado a este ANNOTATION SET é adorocinema-1.
Como não temos um segundo usuário, vamos criar também outro annotation set e atribui-lo ao mesmo usuário (50% que estavam faltando), mas num ambiente real de produção, poderiam ter N annotators e não uma unica pessoa realizando o treinamento do modelo.
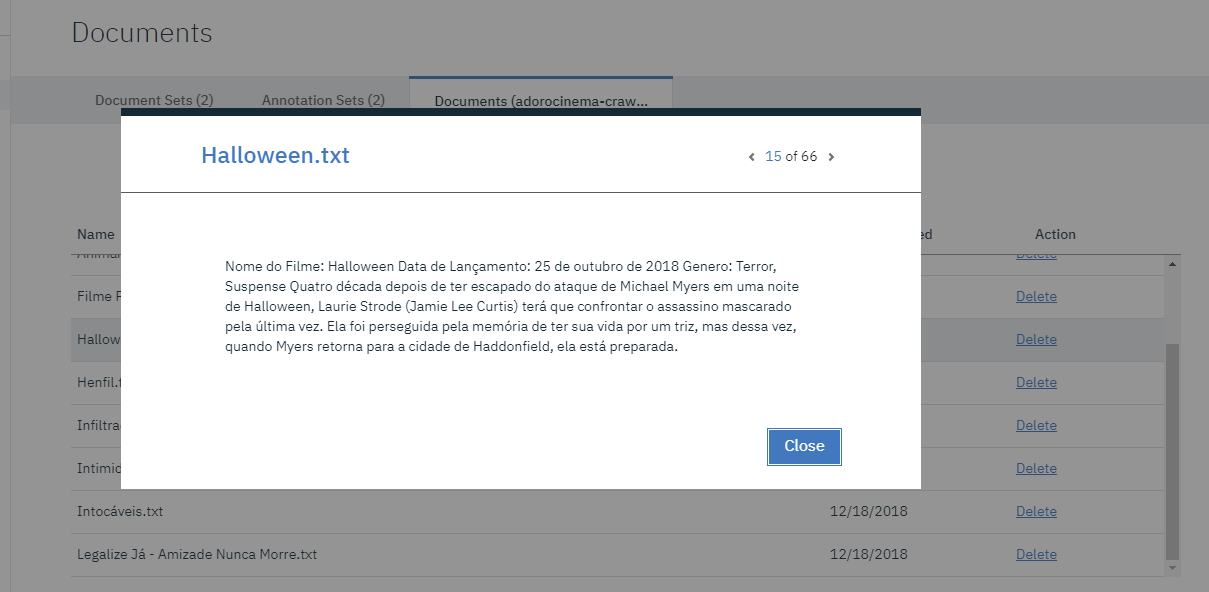
clicando na aba DOCUMENTS, você pode ver o conteúdo individual de cada um dos documentos importados.
Etapa 2 – Treinando o modelo (MACHINE LEARNING MODEL)
PRE-ANNOTATION
Antes de iniciar o treinamento manual com os annotator, é possivel gerar pré-anotações baseadas em NLU e/ou DICTIONARIES criados durante a fase de preparação do modelo.
- Dictionary: Uma vez que você tenha atribuído um dicionario a uma entidade, você pode processar esta pré-anotação. A ferramenta vai marcar todas as entradas que encontrar nos documentos referente a este item
- NLU: Watson Natural Language Understanding é um servico de NLU do watson que pode ser aplicado pra identificar algumas entidades comuns que já foram treinadas. Exemplo: Pessoas, veículos, empresas, lugares.
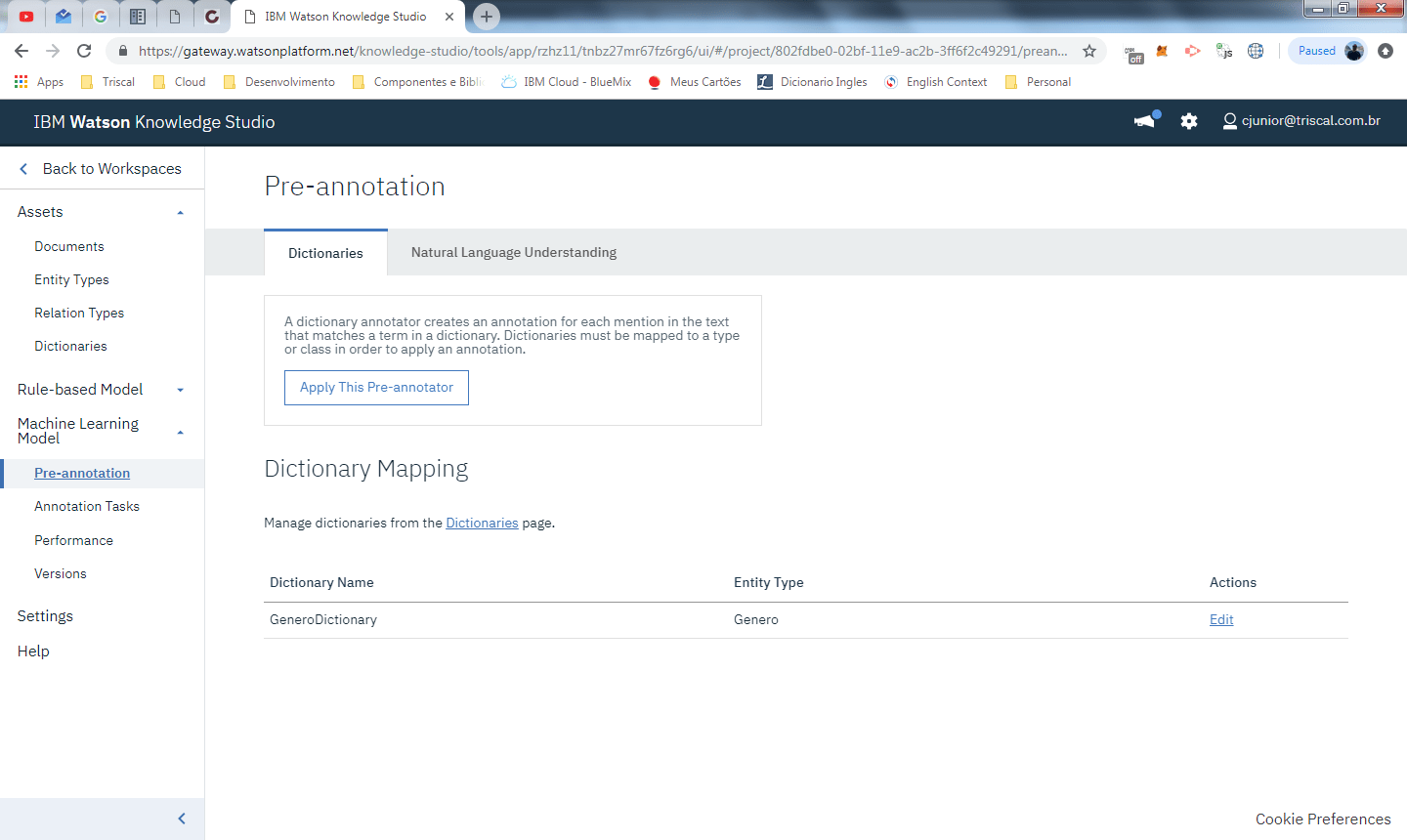
Vamos executar as duas pré-anotações, começando pelo dictionary. Clique em Apply This Pré-annotator enquanto encontra-se na aba Dictionaries, será exibia a opção para você selecionar os document sets ou annotation sets, marque todas as opções e clique em RUN.
Será exibido no canto superior direito a mensagem

pronto, o treinamento do modelo baseado no dicionario já foi executado, agora vamos executar a pré-anotação baseada em NLU. Neste caso, clique na aba Natural Language Understanding e faça o mapeamento entre as entidades de NLU e as entidades que você criou para o seu modelo.
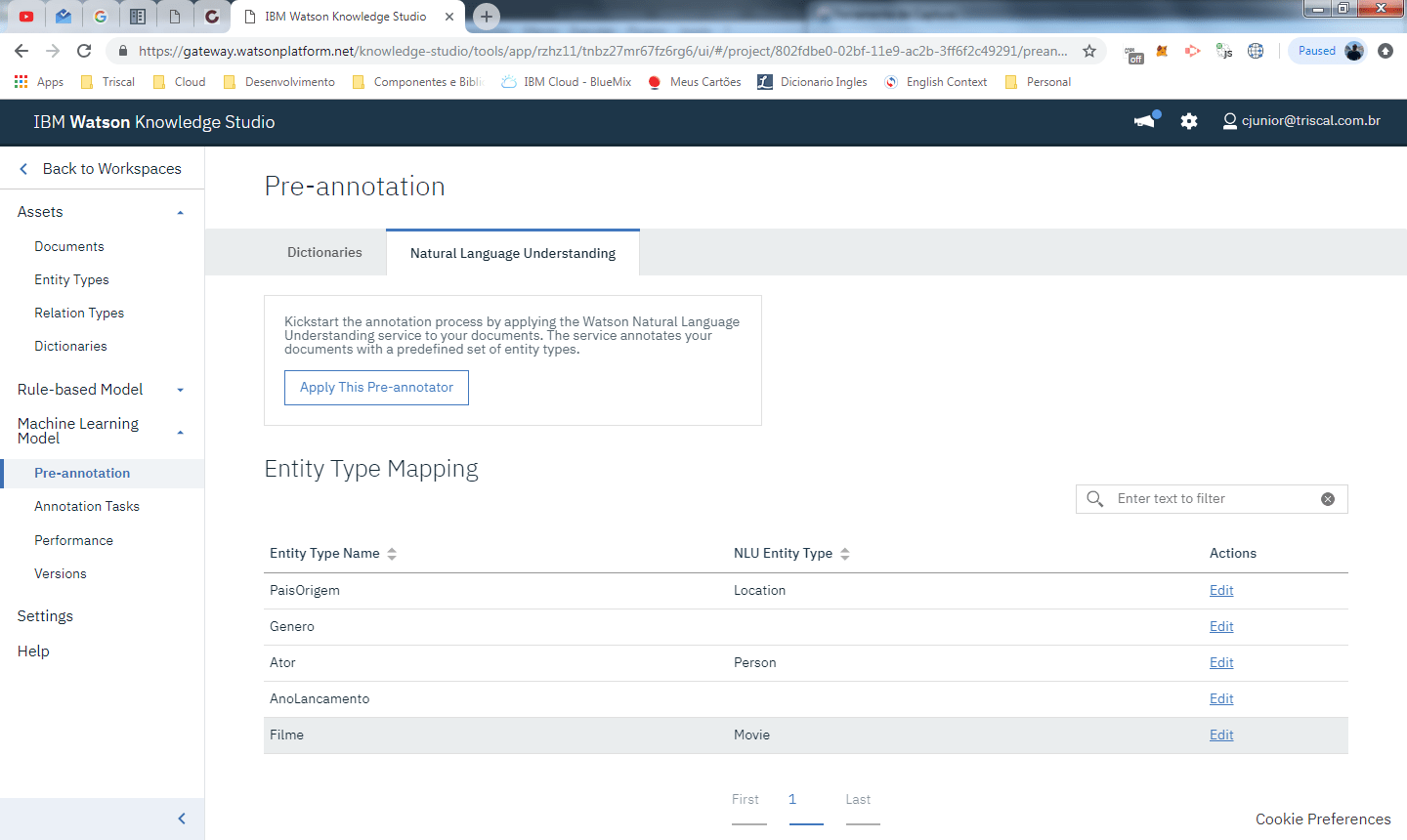
O que estamos fazendo na imagem é acima é aproveitando instruções que o watson já sabe e co-relacionando ao nosso modelo. O Watson já sabe por exemplo identificar lugares (locations), o que inclui paises, que é o que o nosso modelo precisa aprender em PaisOrigem, o mesmo para ator, que é uma pessoa e o nome de filmes.
Novamente clique em Apply This Pré-annotator, selecione todas as opções e clique em RUN. Aguarde o processamento até que a mensagem abaixo seja exibida. Com isso concluimos as pré-anotações.

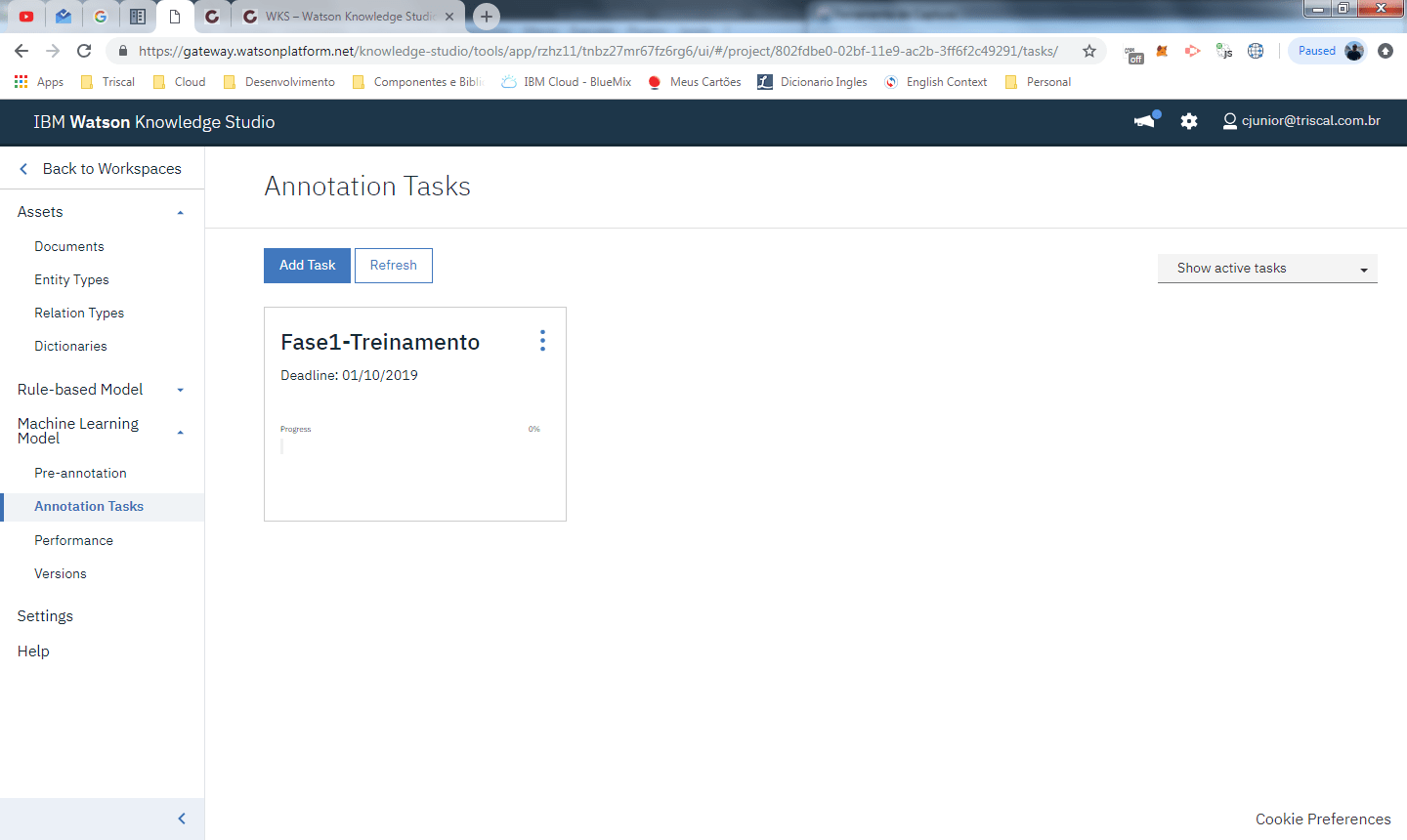
ANNOTATION TASKS
Nesta etapa ja temos organizados os SETs de documentos e annotations (1ª etapa) e eles ja foram atribuidos aos respectivos annotators. Neste momento são criadas as tarefas, que indica quais documentos devem ser treinados até uma data X. Este quadro permite que o gerente da tarefa possa acompanhar o progresso de cada treinamento.
Para cada uma das tarefas voce escolhe quais ANNOTATION SETS estão atribuídos a ela.
HUMAN ANNOTATION – GROUND TRUTH EDITOR
Criadas as tarefas podemos dar inicio a as anotações. Clicando na tarefa você é direcionado para a tela de controle de anotações:
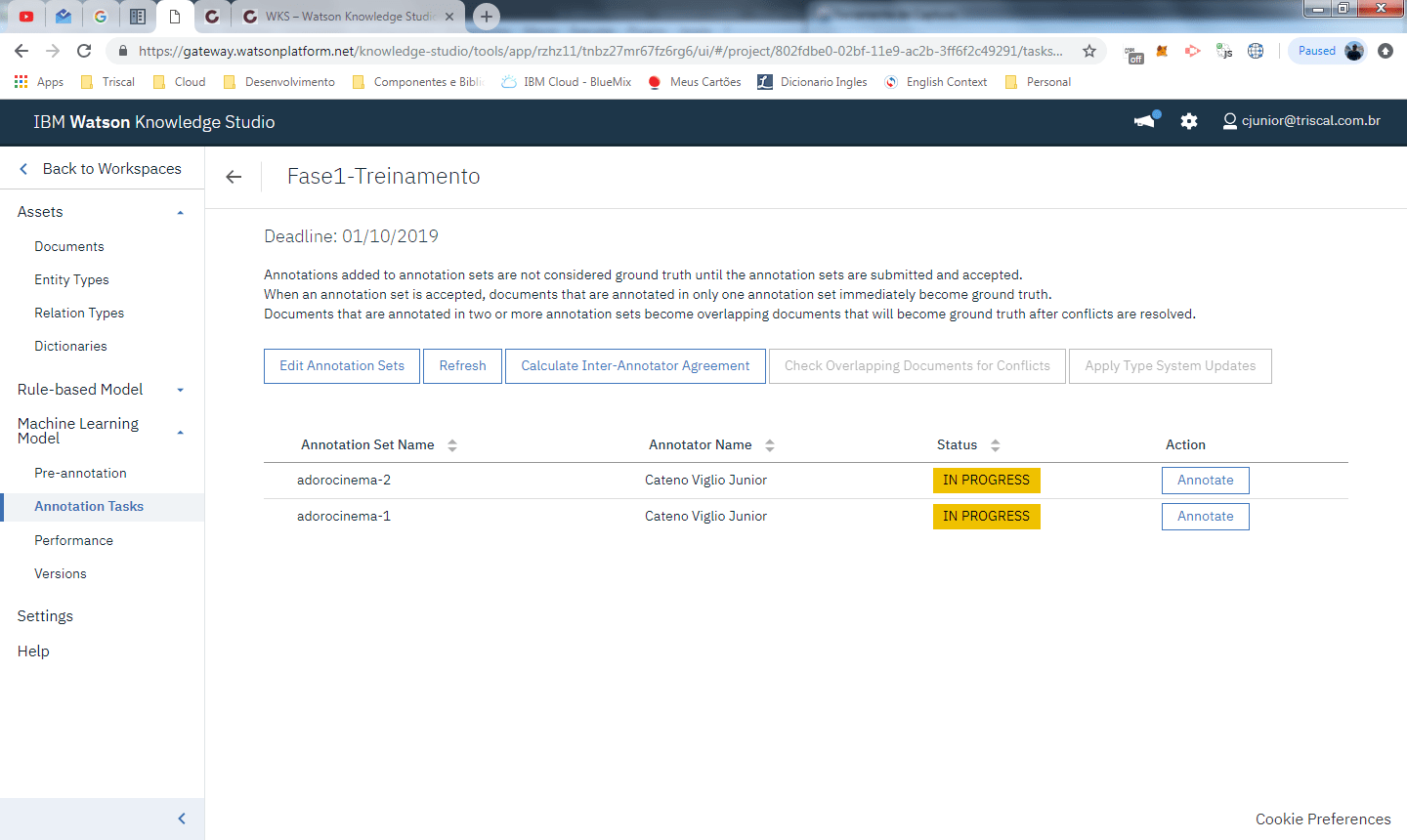
Na tela acima, são exibidos todos os ANNOTATION SETS da tarefa Fase1-Treinamento. Ao clicar em ANNOTATE, são visualizados todos os documentos incluídos no annotation set atribuído a tarefa.
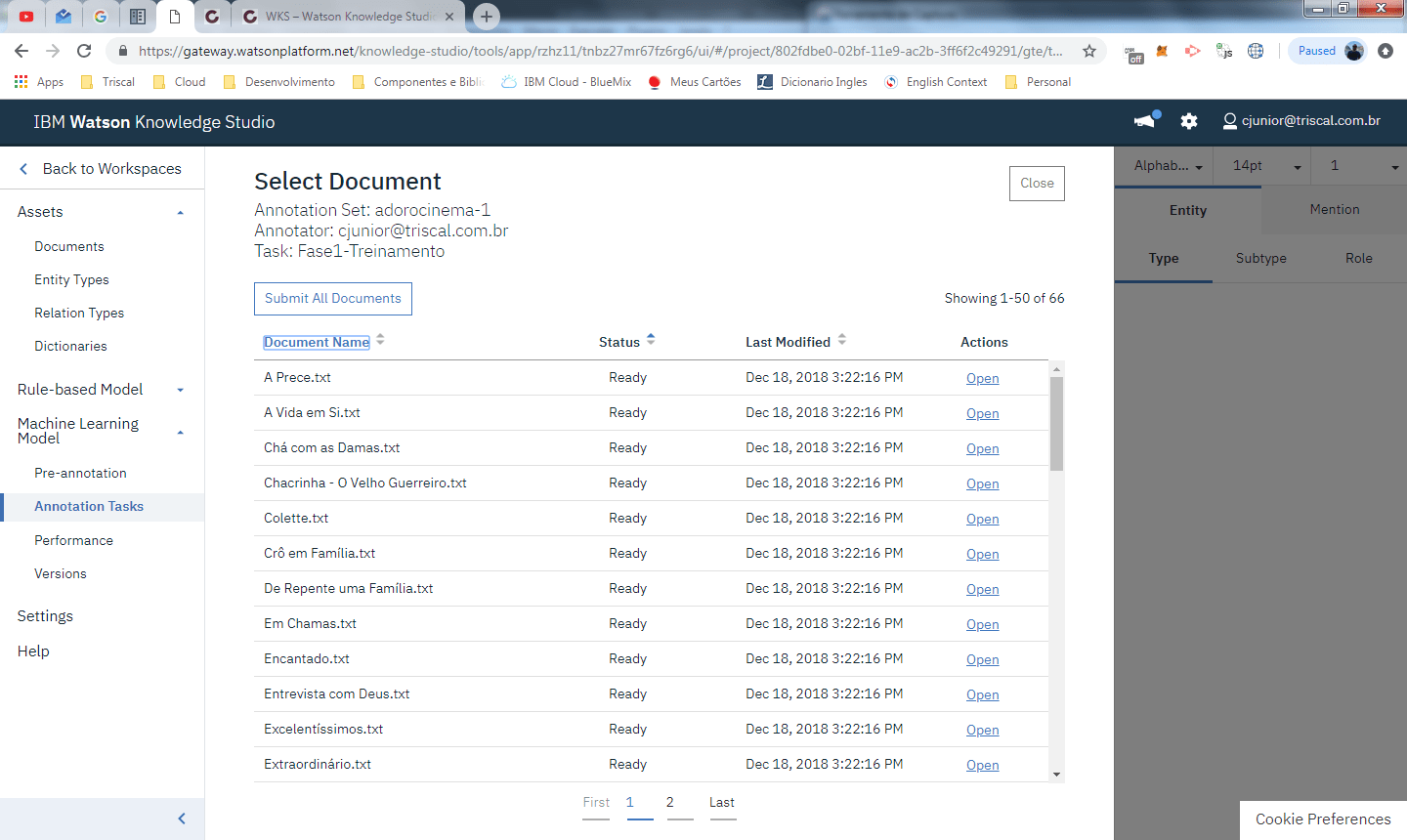
Ao clicar em open é exibido o editor de anotações
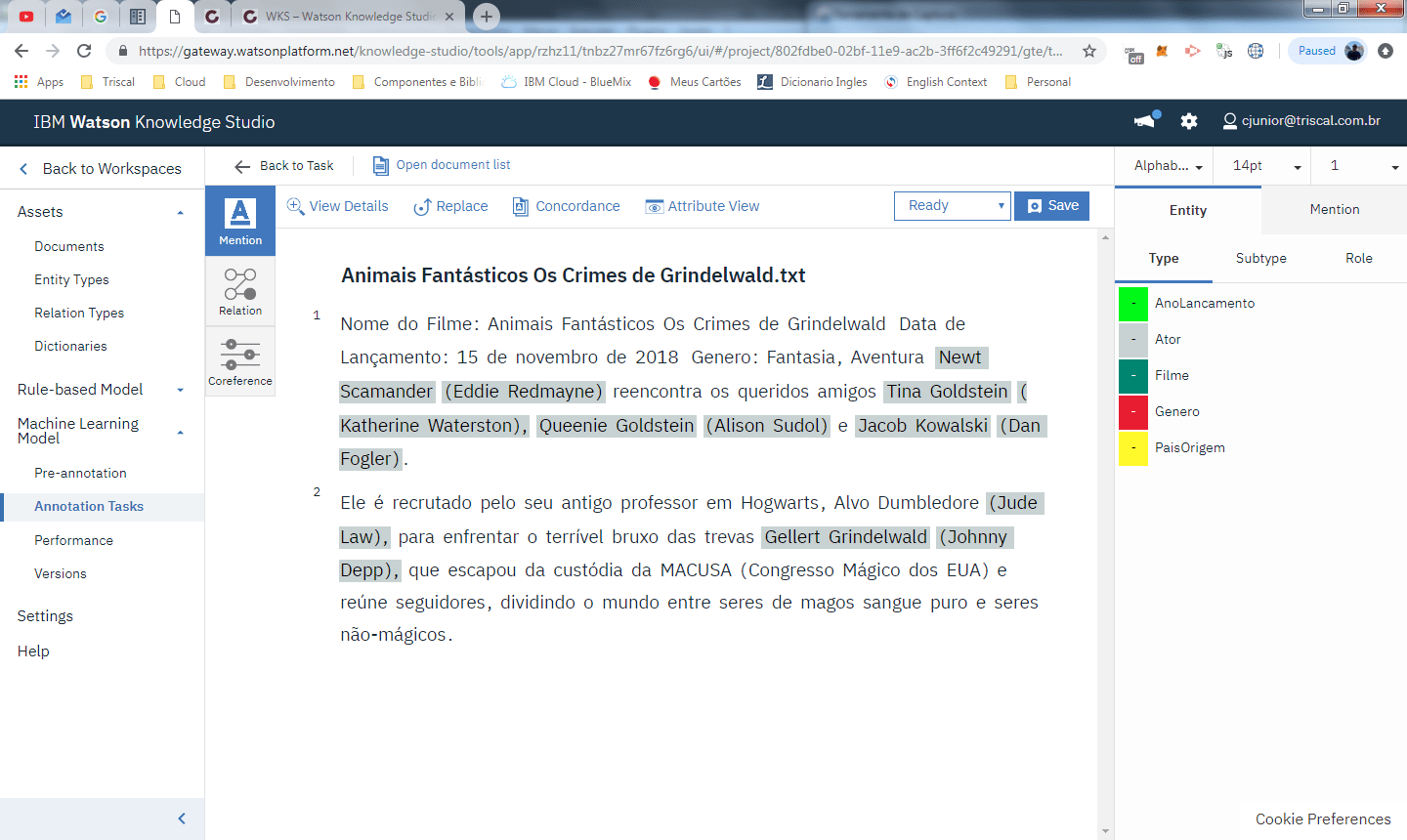
repare que os nomes ja vieram marcados pois associamos na pré-annotation de NLU uma co-relação entre atores e pessoas. Abaixo temos o modelo anotado pelo annotator apos identificação das entidades
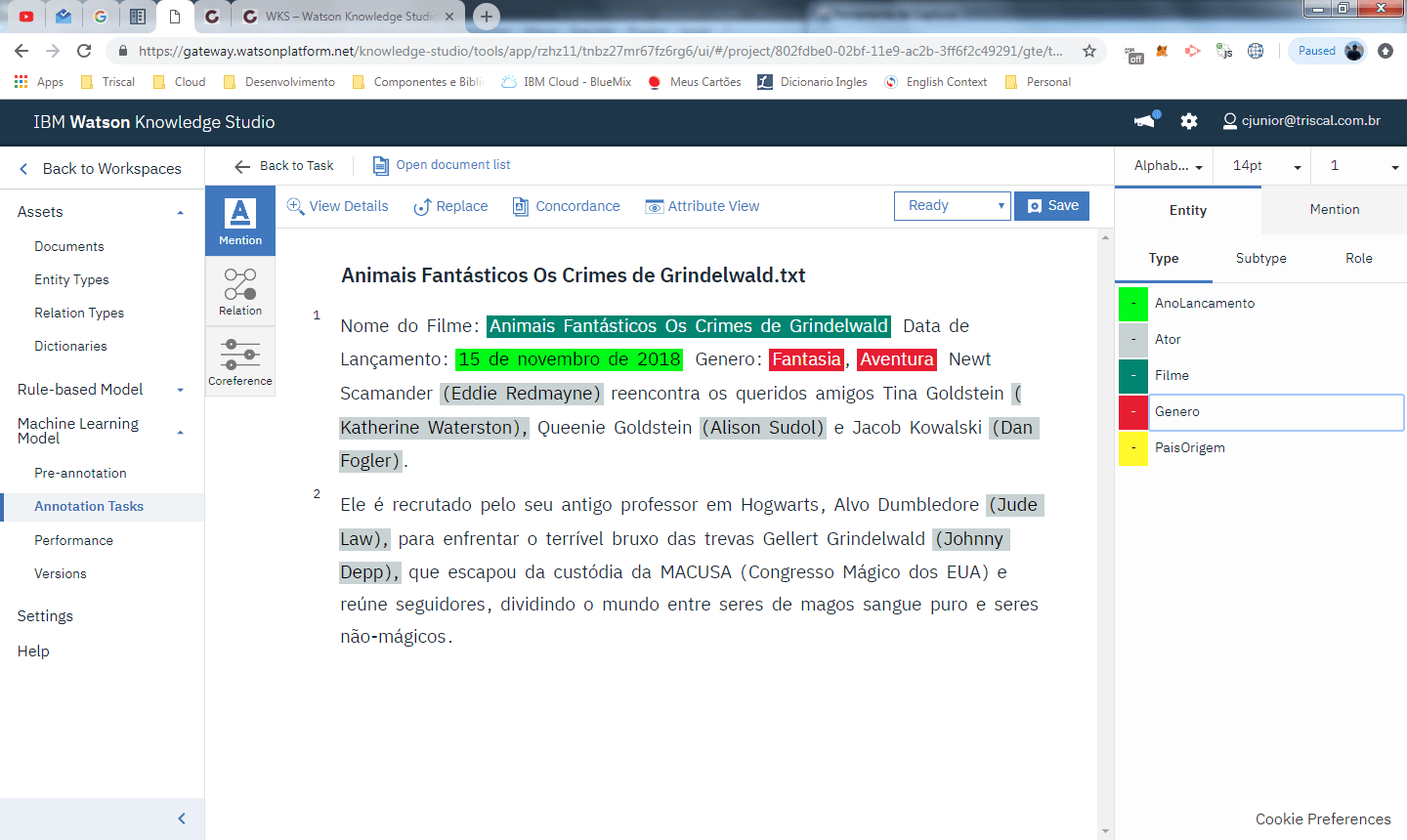
foram marcadas as entidades que identificam o nome do filme, o ano de lançamento e o gênero. Foram excluídos também os nomes dos personagens, pois os nomes dos atores estão entre parentese e precisamos treinar o modelo para que ele entende que os atores são sempre os nomes que encontra-se com essa característica.
Como podem ver o editor de ground truth é uma ferramenta que requer do usuário uma interpretação das entidades e relações, o que faz com que um mesmo documento possa ter marcações distintas se encaminhadas a pessoas diferentes. O treinamento de um modelo de machine learning, não é uma tarefa trivial que possui uma receita de bolo, muito do treinamento que é feito aqui pode ser retreinado e reconfigurado até que o modelo atenda as suas necessidades.
Caracteristicas do editor de ground truth
- No centro temos o identificador do documento importado (nome do documento) e o conteúdo do documento (texto dentro do arquivo txt importado)
- A direita temos os itens principais pra marcar o texto, sao as entidades e menções que devem ser arrastadas para o texto da forma que seja possível para a I.A entender o contexto dos documentos.
- Leva um tempo para se acostumar com a ferramenta, mas em algumas horas o uso torna-se bem natural.
- Use a tecla DEL para deletar uma marcação
- Clique no identificador do documento (no exemplo é o texto em bold) para limpar a seleção atual
- Ao marcar um dos itens com a entidade desejada, clica na caixa de subtipo para especializar a informação e melhorar o resultado do treinamento da I.A (caso tenha utilizado subtipos)
- É importante conhecer bem as entidades e seus subtipos pra fazer as marcações de forma correta. Entidades que parecem semelhantes, talvez devessem ser inseridas no dicionario ou subtipo e nao como duas entidades distintas (exemplo: num modelo financeiro temos fatura e cobrança)
- A aba mention também é importante para informar uma negação e outros identificadores do texto
- Ao finalizar a edição do documento, voce deve selecionar a opção “In Progress” ao lado do botão “Save” e altera-la para “Completed” e clicar em “Save”.
- Apos completar um documento você nao pode mais edita-lo. Clique em “Open document list” no menu superior para retornar a lista de documentos da tarefa.
- Quando finalizar todos os documentos, o status da tarefa vai mudar para “SUBMITTED”, nesse momento o gestor das tarefas precisa revisar e aprovar (no caso deste exemplo eu mesmo vou aprovar as mudancas). Clique na checkbox a esquerda do annotation set que foi finalizado e clique em accept. Caso voce clique em “Reject” o status retorna para “In Progress” e o usuário pode editar novamente os documentos
- attribute view: é possivel ver informações mais detalhadas sobre cada marcacao, pois sao apresentados todas atribuições da marcação.
- concordancia: esta funcao ajuda bastante a acelerar as anotações pois permite que uma marcacao aplicada no documento seja replicada em todos os outros, mesmos os que nao foram atribuídos a você.
- No canto esquerdo superior temos 3 blocos de edicao, Mention, Relation e Coreference. O padrao é o Mention que foi explicado agora acima.
Relation
Nesta interface você deve selecionar as marcações e fazer relações entre elas, muito parecido com a modelagem de um banco de dados relacional ou de um DER.
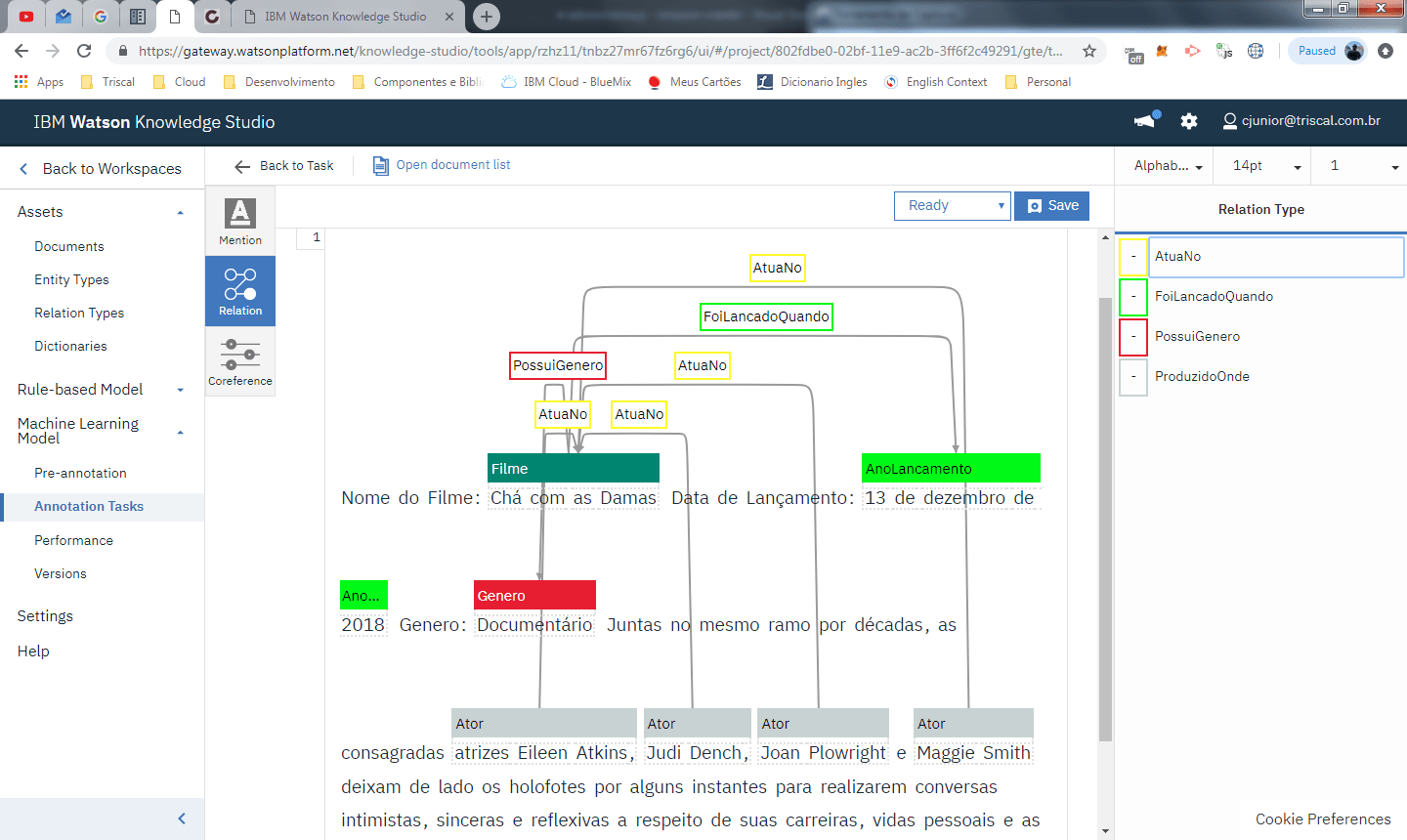
Primeiro clique na entidade de origem, depois clique na entidade de destino e por ultimo selecione a relação.
Coreference
Nesta interface você deve relacionar assuntos em comum, exemplo: supondo que um filme da marvel sempre esteja relacionado ao stan lee, ou um personagem do filme esteja relacionado ao ator que o interpreta. Segure o CTRL e marque as entidades relacionadas, na ultima marcação fazer um double-click na entidade que ela sera incluída no quadro a direita:
Caso modifique ou crie entidades/relações novas, elas somente estarão disponíveis para as novas tarefas que forem criadas. Neste caso as tarefas podem ser excluídas e criadas novamente caso seja necessário. Uma boa pratica pra evitar esse tipo de problema é analisar alguns documentos antes de iniciar o processo de criação das atividades, criando tarefas e sets com poucos documentos e ir aumentando aos poucos
Com isso fechamos a primeira parte do WKS, excelente ferramenta da IBM que permite o treinamento de um modelo de machine learning pela própria equipe de negocio.
Sei que o WKS no primeiro momento pode ser um pouco confuso, principalmente quando falamos do editor de ground truth. Caso tenha ficado com duvida deixe no comentario que tentarei ajuda-los.
em breve darei sequencia a parte 2.



{kind=link}